- 22 Dec, 2020
- read
- Majid Fatemian
With growth of microservices in the past few years, gRPC has gained a lot of popularity for inter-communication among these smaller services. Behind the scenes gRPC uses http/2 to multiplex many requests within the same connection and duplex streaming.
Using a fast, very light, binary protocol with structured data as the communication medium among services, is indeed very attractive, but there are some considerations when using gRPC, most important of all is how to handle load balancing.
gRPC uses sticky connections
gRPC connections are sticky. Meaning that when a connection is made from client to the server, the same connection will be reused for many requests (multiplexed) for as long as possible. This is done to avoid all the initial time and resources spent for tcp handshakes. So when a client grabs a connection to an instance of the server, it will hold on to it.
Now, when the same client starts sending large volumes of requests, they will all go to the same server instance. And that is exactly the problem, there will be no chance of distributing that load to the other instances. They all go to the same instance.
That is why a sticky connection, makes the load balancing very difficult.
Below are some approaches to load balancing gRPC inter-communication and some details with each approach.
1. Server-Side
When load balancing is done on the server-side, it leaves the client very thin and completely unaware of how it is handled on the servers:
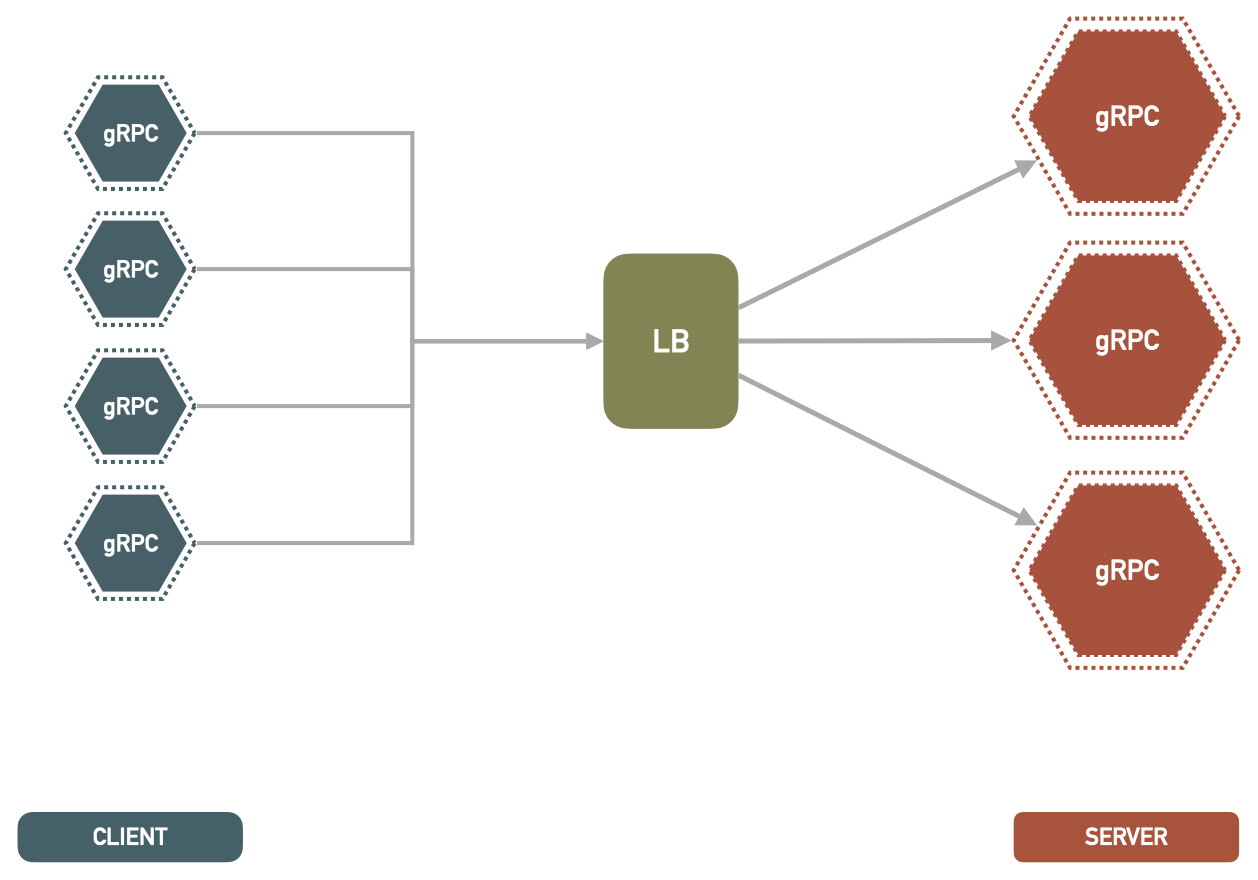
Network Load Balancers
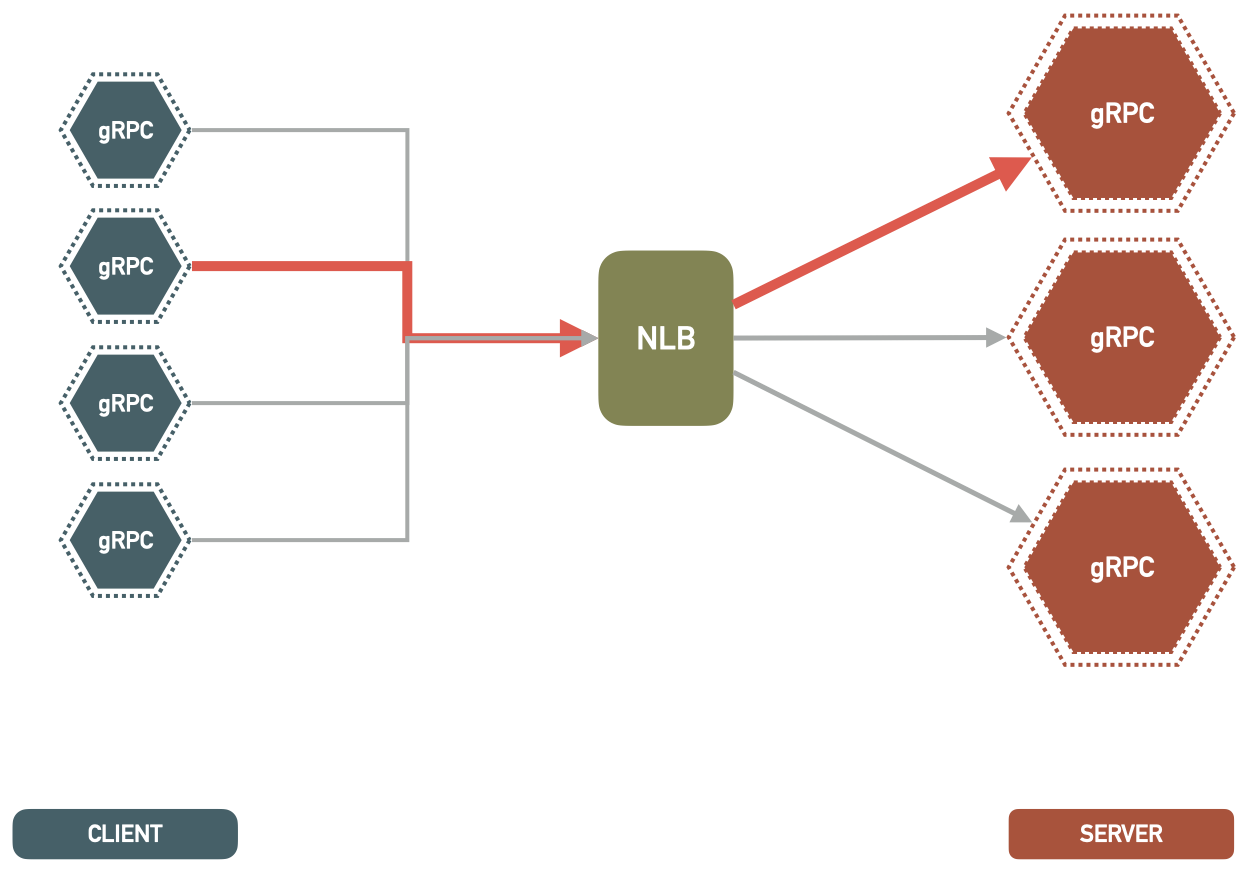
A Network Load Balancer operates at the layer-4 of OSI (Open Systems Interconnection) model. Therefore it is very fast and can handle much more connections. When a new TCP traffic connection comes in, the load balancer selects an instance and the connection is routed to that single instance for the life of the connection.
Remember now that gRPC connections are sticky and persistent, so it will hold on to the same connection between the client and same server instance behind the load balancer, as long as it can.
Now here is the problem:
⚠️ Sticky connections and Auto Scaling
If load (memory or cpu) on a single server instance goes higher than the auto scaling policy, it will cause a new instance(s) to be spun up in that target group.
But a new instance in the target group is NOT going to be helpful. Why? Again, because gRPC connections are persistent and sticky. The client that was sending large volumes of requests, will keep sending them to them same server instance it has the connection to.
Therefore new server instances are spun up, but none of the requests overload is going to the new instance(s). Same single server instance with heavy usage is still receiving loads of requests from the client (as the client keeps reusing the same connection).
There is a chance that the auto scaling policy keeps triggering and adding new instances to the target group (as there is a single instance with overloaded cpu/memory). But these new instances receive close to zero traffic. The auto scaling policy could keep triggering and potentially maximizing the allowed instances in the target group, without actually benefiting from the requests being sent to the new instances.
How to distribute the load with gRPC sticky connections?
To have a chance of distributing the load basically we have to give up the stickiness and persistent connections with one of the following approaches:
1. clients to reconnect periodically
If you have control over the connecting gRPC client, you can force the client to disconnect periodically and reconnect. This act will force the client to send a new request to the load balancer and as a response to this request this time a healthier instance will be returned. This technique forces the load to be balanced.
2. Server forcefully disconnects the clients periodically
If you do NOT have control over the connecting gRPC clients, you can implement similar logic on the server side. Making the server to forcefully shut down the connections after sometime, and when they reconnect, it automatically causes the new connections to go to the healthier instances.
Either of these approaches defeats a fundamental gRPC benefit: reusable connections.
Application Load Balancers
AWS Application Load Balancers are a layer-7 load balancer and support http/2, up until Oct.2020 the support for http/2 was from the client to the load balancer only. Then the connection was downgraded to http/1.1 from the load balancer to the backing target instances behind the ALB.
Therefore previously you could not use ALB with gRPC as it requires http/2 all the way through.
But on Oct.29.2020 AWS announced that ALB now supports the http/2 all the way, making it a great fit for gRPC communications.
Although this feature from ALBs is relatively new but the arguments for sticky gRPC connections and NLB are also applicable with ALBs. If you end up with a single sticky and persistent connection from a client that starts sending a large volume of requests, you are overloading a single server instance that holds that connection and the requests are not being load balanced as they should.
DNS Service Discovery
Similarly we can put our server instances behind DNS Service Discovery, instead of an Elastic Load Balancer. Service Discovery is basically a DNS service that when a request comes in, it will return the list of IP addresses for all the instances behind it (or a subset of the healthy ones), in random order. So when a client is choosing which server to connect to, and does a DNS lookup, service discovery returns back the IP addresses of backing instances sorted.
Pretty much all the concerns with NLB are applicable to DNS Service Discovery load balancing as well. When a client grabs a connection to a single instance it will stick to it and keep reusing it. No matter how it has found the server instance, be it ALB, NLB or Service Discovery.
2. Client-Side
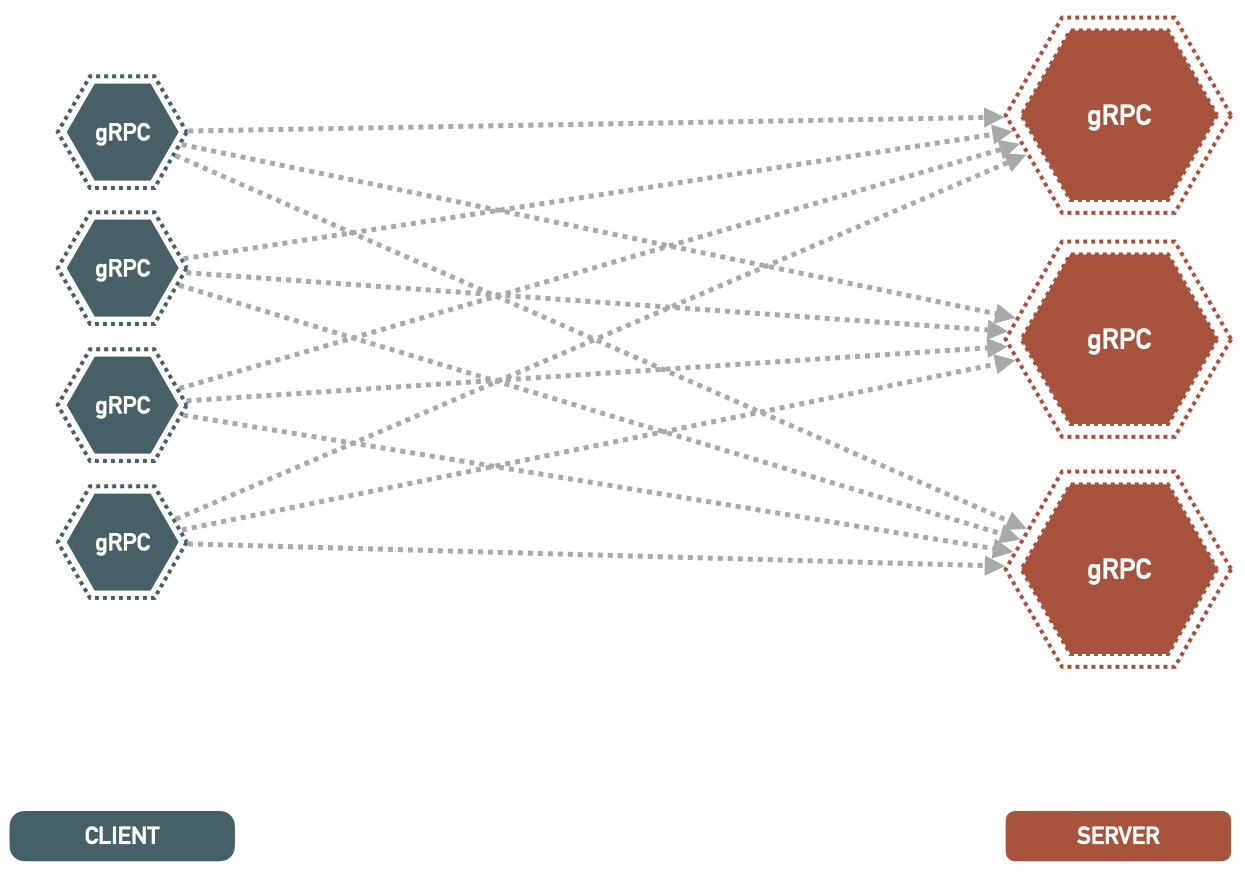
If you have full control over the clients, you can implement load balancing logic in the client-side. Making the clients aware of all the available servers and their health and choosing which one to connect to. This will cause the clients to be heavier in the logic. So they not only should contain the logic to do what they are supposed to do, but also they also need to implement the logic for load balancing, health checks, etc.
This is a viable option, under one condition: If you have full control over all the clients. You can’t let faulty clients connect to your service and cause all sorts of load balancing issues. It only takes one faulty client to cause enough troubles.
3. Look-Aside
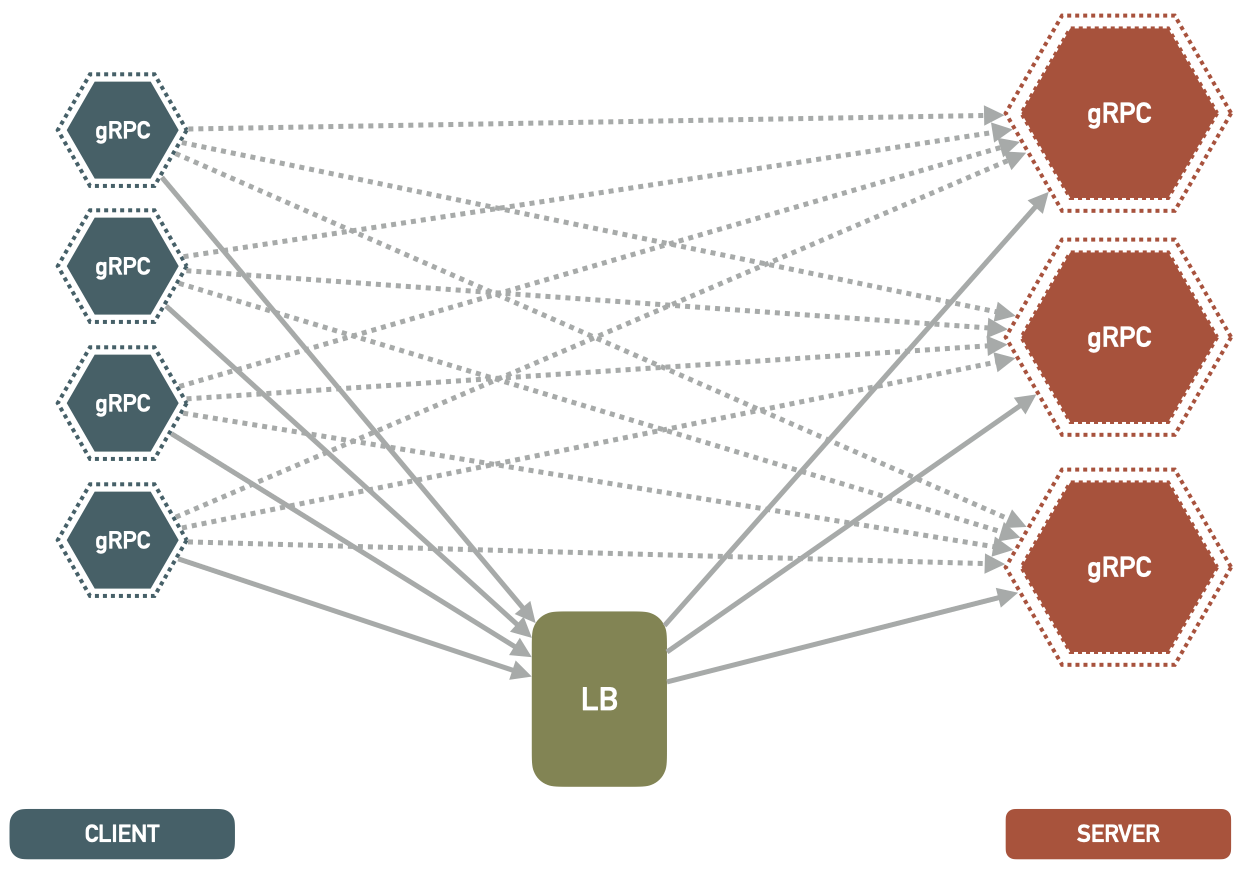
As recommended by the official gRPC load balancing, this method is using an external load balancer or one-arm load balancer for distributing the traffic between server instances.
Client reaches out to an external service and it will return a list of available servers, service discovery and all other required information.
Ideally there will be some logic in the client-side as well to help making the decision. This approach is prone to the problem with sticky connections that is mentioned above, so it needs to be implemented carefully.
The official implementation uses a Per Call Load Balancing and not a per connection one. So each call is being load balanced separately. This is the ideal and the desired case and it will avoid having heavy sticky connections.
Look-aside checks all the boxes, but with one big drawback: It requires a fully dedicated service.
So to benefit from look-aside load balancing, you need to implement and deploy a brand new dedicated service to just load balance the gRPC connections between your other service. Every new service comes with its own maintenance, operation, monitoring, alerting, etc.
Conclusion
Server-Side load balancing, has very important concerns, we can not benefit from one of the main advantages of gRPC which is sticky reusable connections.
Client-Side load balancing, requires full control to the clients, if there is one faulty client, it could break all the plans.
Look-Aside load balancing, is the most logical and performant solution to load balance gRPC connections, but then it requires a full and dedicated service of its own, meaning a new service in your architecture to implement and operate. Also a new point of failure.
The concern and challenge of handling the increase in load in a gRPC architecture is an important one. It needs proper attention to be handled properly and the solution depends on the situation and how much control we have.
The complexity of gRPC load balancing also provokes some important questions:
- Should the communication necessarily happen over gRPC?
Or more fundamentally:
- Should those communications happen at all?
- Does architecture need to be implemented as all those tiny little independent microservices?
Finally, as everything else in software engineering, gRPC comes with trade offs. It’s critical to be aware of the trade offs and choose accordingly.
If you have found this article interesting Follow @majidfn as I share my learnings.